ずいぶん公開に時間が経ってしまった。6/4 か。。。特に出せなかった理由はない。より「ちゃんとした」形で出したいと思っていたが、そんな日はこないので当時のまま公開する。
WSA 研に初参加し、はじめて自分の身の回りの仕事、SRE の関心対象に対して計測を行なった。当時は本当に手探りであったが、この時泥臭くデータを取り、考察したことが2ヶ月後の今に確実に繋がっている。貴重な機会をくれた WSA研のメンバーに感謝したい。
当日は参加者からたくさんフィードバックをもらえた。その時いただいた意見は今に活きており、より実務に生かすことができている。
修士卒業以来久しぶりに「研究」っぽいことをしたが新鮮で楽しかった。ビジネスと研究、行ったり来たりするのいいかもな、と思った。
本資料は第8回WebSystemArchitecture研究会の予稿です。
以下が当日使ったスライドです。
背景
Site Reliability Engineering(以下、SRE)はインフラ・サービス運用をソフトウェアで制御することで、スケーラビリティや信頼性を担保する役割である。また、SRE は DevOps を実装しているという見方もあり*1、サービスのデリバリーを高速に繰り返すことにも関係が深い。加えて、システムの信頼性のためにはクラウドを含めたインフラの管理や設計にも関わるなど、その業務範囲は多岐に広がる。そしてこれらはビジネス・組織の規模や性質、組織内の分担によっても大きく異なる。そのため、多くの企業で SRE をどう採用し、どのように活かすのかの解答を探すのが難しい。*2
加えて、ソフトウェア・プロダクトを開発して利益を得る企業のプロダクト開発組織は、通常ビジネス KPI を定め、その改善のために開発を行うが、SRE の場合そういった指標を持って改善を行う"プロダクト開発的なアプローチ"はまだ一般的ではない。ただし、DevOps 領域においては書籍 「Lean と DevOps」の科学」*3でのキーメトリクスとして「デプロイの頻度」「変更のリードタイム」「MTTR」「変更失敗率」が紹介されており、エリート企業はこのどれもが優れていることが報告されている。
本発表では、前半で、筆者が所属する企業*4での経験を元に、SRE の業務領域のうち、重要な領域とその領域ごとの関係性について考察する。これによって、同様な規模の組織における SRE の活動方針のモデルを定義する。後半では前半で定義した領域のうち、2つに着目し、「Lean と DevOps の科学」の紹介内容を拡張しながら、プロダクト開発的なアプローチを SRE 業務全体に適用できるパフォーマンス指標とその測定方法を提案する。
SRE が扱う5つの領域
SRE が扱う領域は企業によって異なる。本研究では、筆者が所属する Quipper Ltd. が提供するサービス*5のように、クラウド上での Web サービスを提供する企業の SRE が関わる領域を考察していく。
クラウド上でサービスを構築していることから、今回、AWS Well-Architected*6 Framework を参考にした。この資料によると、Five Pillars として「Operational Excellence」「Security」「Reliability」「Performance Efficiency」「Cost Optimization」があげられている。AWS Well-Architected はクラウドアーキテクトが、スケーラブルで信頼性のあるクラウドインフラを構築するためのガイドである。
「Lean と DevOps の科学」と「AWS Well-Architected」の両者を参考にしつつ、筆者が所属する環境では以下の5つを重要領域だと捉えた。
- Reliability
- Developer Productivity
- Platform
- Security
- Cost
1つずつ内容を説明する。
Reliability
その名の通り、Site(Service)の信頼性である。AWS Well-Architected でいう「Reliability」「Performance Efficiency」が関連する。
Developer Productivity
開発者生産性である。DevOps が関連する。
Platform
Kubernetes などに代表される、Application Platform を開発者に提供している。
Security
AWS Well-Architected にも存在する。また、インフラだけに閉じず、Security Incident は一度起こすと一気にビジネスが破綻しかねない重要な要素である。
Cost
AWS Well-Architected にも存在する。クラウドに限らず、コンピューティングリソースを使うために Cost は発生する。
領域の関係性
これら5つの領域はそれぞれが密接に関わっている。
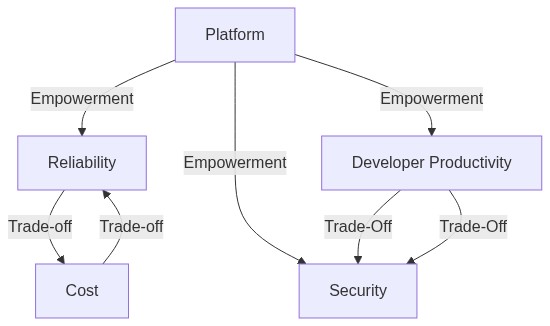
以下、その関係性について説明する。
Platform の特性
Developer のための Application Platform は、それ自体がその上のレイヤーの他の全ての分野を支える関係性にある。
Trade-off
- Reliability(可用性)をあげようとするとコストがあがる。99.9% という数字で表される Availability の桁を1つあげるには非常に大きな労力がかかる。*7
- Security を高めようとすると、利便性, Developer Productivity を損ねる可能性がある
提案指標と測定方法
今回は5つの領域のうち、「Lean と DevOps の科学」に関連が深い"Developer Productivity" と、SRE の本丸である"Reliability" の2つの領域に絞って指標を提案する。
Reliability
Site "Reliability" Engineering を考える上で、サービスの安定稼働は第一のミッションであり、いかに他の指標を満たそうともサービスの信頼性を落としては意味がない。
しかし、サービスの可用性を指標にはしない。サービスレベルはビジネス要求によって異なる。また、サービスレベルを高めるとコストも高まる。サービスレベル目標(Service Level Objectives) として、信頼性と機能開発のアジリティのバランスをとるためのツールでしかないので、この数値自体を目標値にするのは本質的ではない。
そこで今回は、「Lean と DevOps の科学」でも紹介されていた、"MTTR / Mean time to recovery" を採用した。これを小さくするために、障害を局所化したり、すぐに復旧できるようにする必要がある。*8
MTTR 測定の自動化は非常に難しい。"障害"の判定基準は企業により異なるからである。仮に可用性(Uptime)を採用したとしても、それだけでは全てのシステム障害をカバーすることはできない。そのため、障害と判定されたインシデントの報告フローに MTTR を項目として組み込んで手動で計測する。
なお、MTTR を指標とすべきかどうかは懐疑的な面がある。その一番の理由は障害の発生数が非常に少なく、指標として追いかけるには母数が少なく、ばらつきが大きくなってしまうことが予想されるからである。*9しかし、重要指標であることには変わりなく、数が少ないことは手動でのトラッキングも可能であることから採用した。
Developer Productivity
以下の4つを指標としてあげた。それぞれの指標は開発環境と本番環境両方で区別して計測する。
- デプロイ回数
- デプロイ時間
- CI 安定性
- 変更失敗率
CI 安定性以外は「Lean と DevOps の科学」であげられた基準と同じあるいは似た指標である。また、「デプロイ時間」は該当ブランチにマージしてから、実際にコードが環境に適用されるまでの時間である。「Lean と DevOps の科学」における「リードタイム」は「コードのコミットから本番稼働までの所要時間」であるが、レビューの時間を含むと変数が多くなってしまうため、マージから本番稼働までの所要時間、とした。
CI 安定性は「デプロイ時間」に内包される(CI が失敗すれば Rerun を行う必要があるので、デプロイ時間は長くなる)が、より分析をしやすくするために CI 安定性(CI 成功率)も指標に掲げた。
これらの指標は基本的に CI サービスから取得する。CI サービスがそのような metrics を提供していればそれを利用すれば良い。もし提供していない場合でも、CI の Job / Workflow で時間を計測し、何らかの時系列ストレージに情報を送ることで取得できる。Monitoring SaaS*10では Custom Metrics がサポートされているので、こちらをストレージ兼可視化システムとして採用することができる。
変更失敗率は、コード適用後、何かしらの"不具合"が発生した件数である。これは"不具合"の定義に依存してしまうため、計測が難しい。そこで、原則不具合があった場合は即 Revert をして、その後 HOTFIX を適用する運用とし、本番環境に対応するブランチにおける Revert commit の数を計測する。
指標のまとめ
領域ごとの指標と測定方法をまとめた。
| 領域 | 指標 | 測定方法 |
|---|---|---|
| Reliability | MTTR | 障害発生時に、障害報告フロー内の必須項目として手動で計測 |
| Developer Productivity | デプロイ回数 | CI サービスの metrics |
| Developer Productivity | デプロイ時間 | CI サービスの metrics |
| Developer Productivity | CI 安定性 | CI サービスの metrics |
| Developer Productivity | 変更失敗率 | 本番環境デプロイに対応するブランチの Revert commit の数 |
計測結果
MTTR
以下、筆者が所属する企業で計測した MTTR を複数の観点で図にした。

これは TTR の散布図である。2019年から2020年前半にかけて、1000分以上停止しているインシデントが3件存在している。それ以降はそのようなインシデントはなく、減少傾向にある。

これは半年ごとの MTTR の平均である。2019年後半に MTTR は増大し、その後減少傾向にある。

これは横軸を TTR としたヒストグラムである。Incident Response in SRE Figure2 で紹介されているグラフと近い形を示しており、少数の長時間解決しないインシデントと、多数の短時間で復旧したインシデントがあることがわかる。
デプロイ回数
以下、筆者が所属する企業における、Production に Deploy した回数である。

なお、筆者が所属する企業特有の事情があるので説明する。筆者が所属する企業は monorepo*11 を採用しており、かつ 1つの Database を複数アプリケーションで共有するDistributed Monolithとなっている。この monorepo で master branch に merge された場合、この Distributed Monolith を構成する全サービスがデプロイされる。今回プロットしたデプロイ回数は Distibuted Monolith へのデプロイ回数である。Microservice 化は徐々に進んでおり、その場合別のブランチへのマージを契機に microservice へのデプロイが行われる。
デプロイ回数が減少傾向にあるのは、microservice 化が進んでいるからだと考えられる。
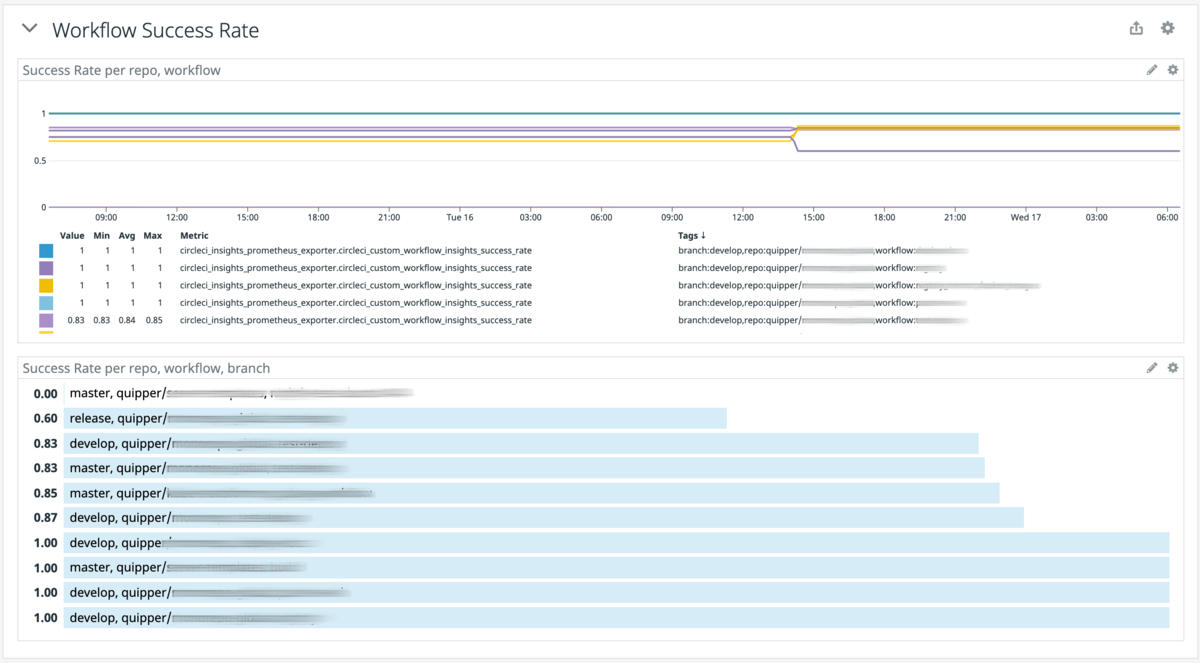
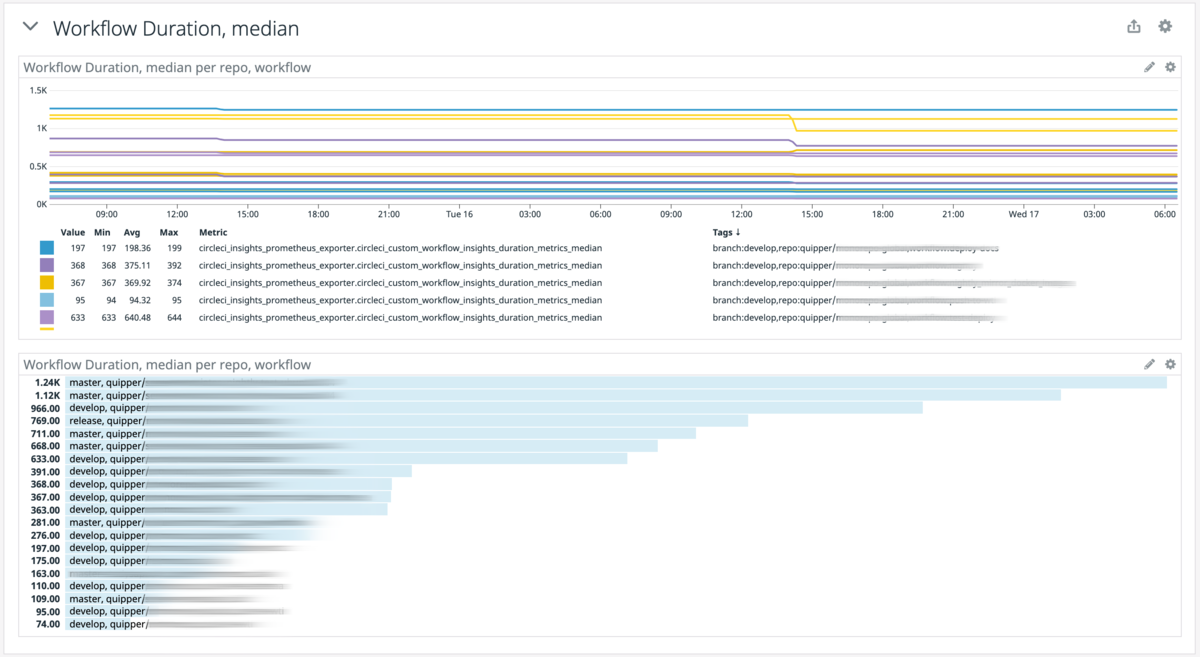
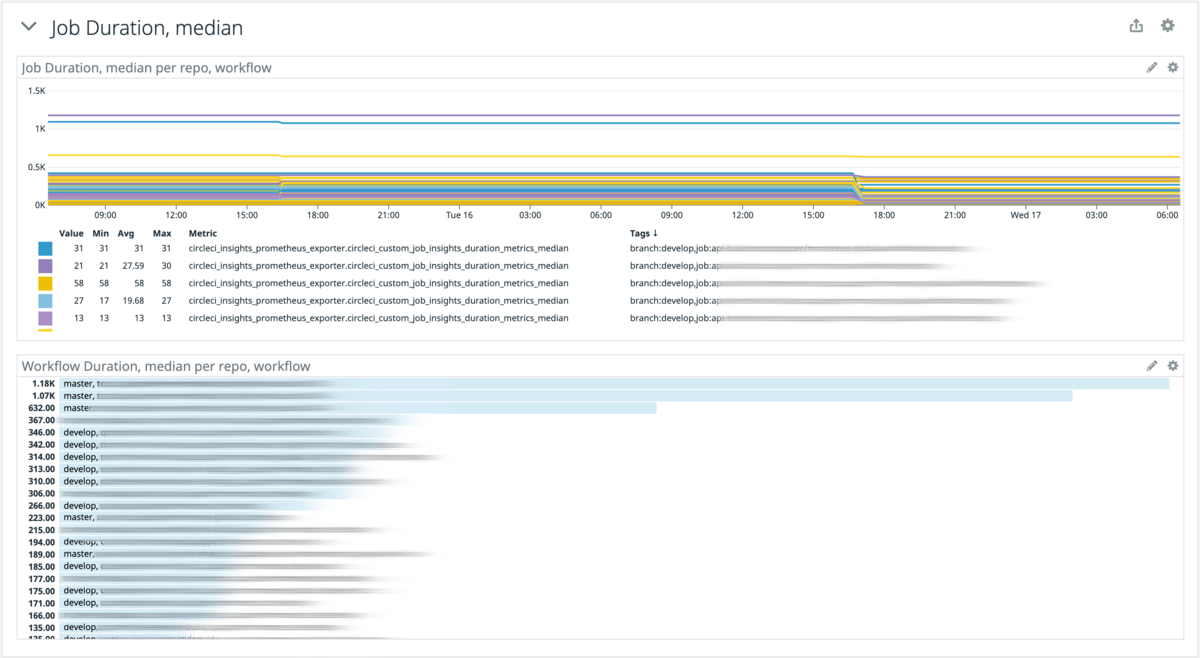
デプロイ時間
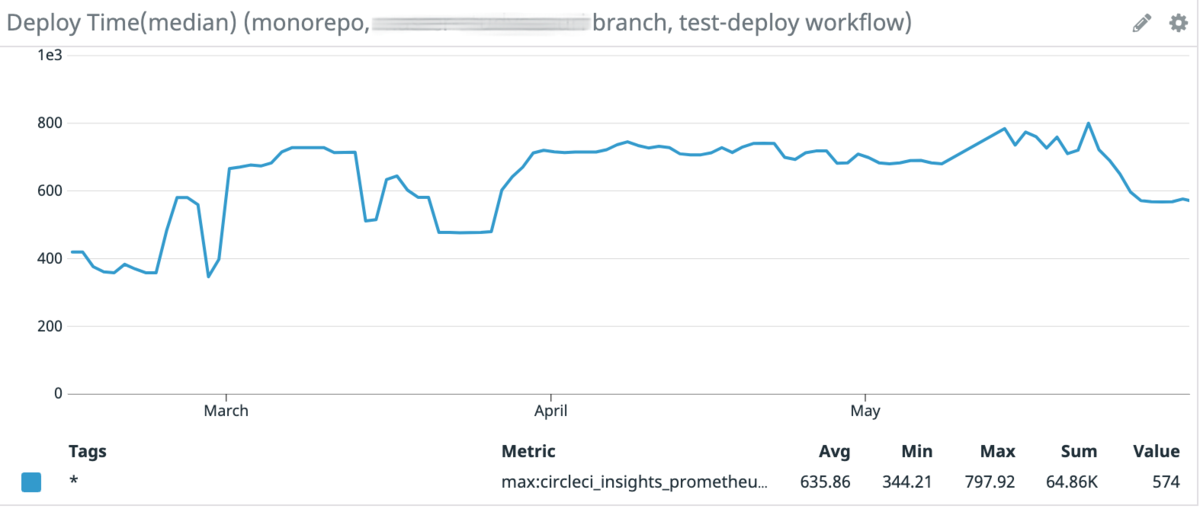
これは master branch の CI Workflow の median である。(Duration Period は 7 Days)なお測定開始は2021年2月である。
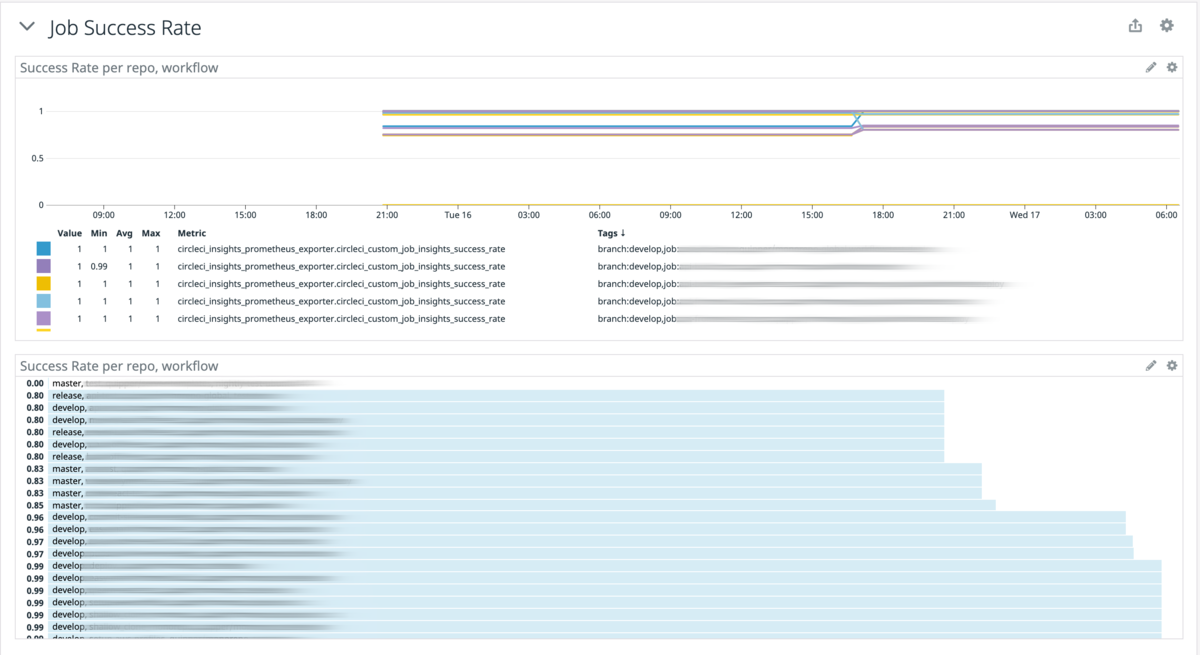
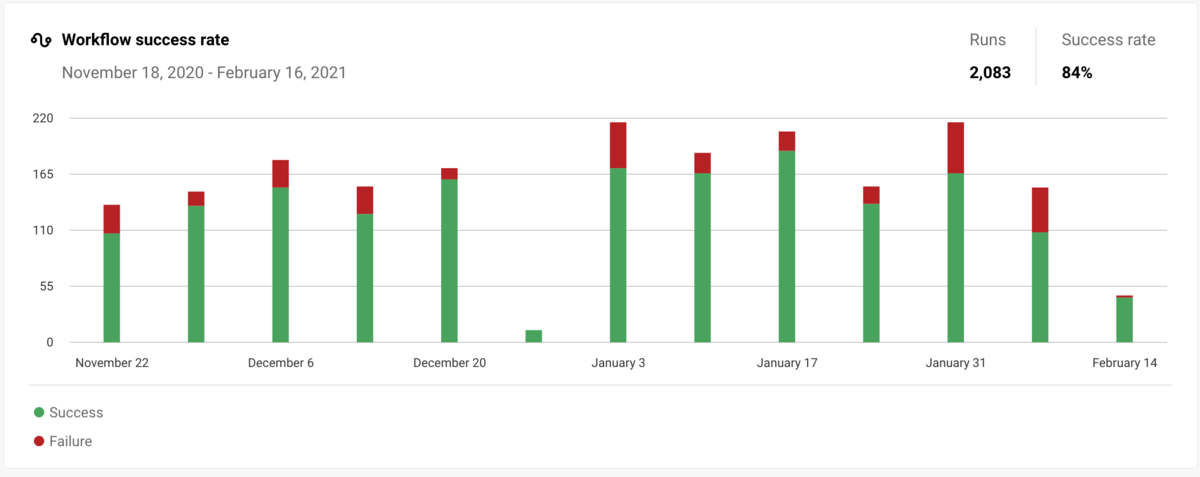
CI 安定性

これは master branch の CI Workflow の成功率である。(Duration Period は 7 Days)なお測定開始は2021年2月である。
変更失敗率

これは master branch を base branch とする、すべての merge 済み PR の数と、"Revert" という Title が含まれている PR の数である。

これは master branch を base branch とする、すべての merge 済み PR の数に対する "Revert" という Title が含まれている PR の比率である。
まず、2020年 1st half に merge 済み PR が増えている理由は、本番環境に対する Kubernetes manifest の変更が行われる場合、develop branch を経由する必然性がないため、HOTFIXとして直接 PR 作成されたことがある。
次に、2021年 1st half に Revert PR が増えている理由として、Argo Rollouts*12による Canary Release を採用している過程で、Canary Strategy を1度有効にして Promotion し、終わったあとそれを Revert する動きが多くあることがあげられる。これは Canary Strategy は通常有効にしておらず、Kubernetes Deployment と同様に Rolling Update を行うが、重要なリリースのみ Canary を行っているためである。
このような事情より、Revert PR は必ずしも変更失敗を示していないため、別の方法での変更失敗率の計測が必要である。
まとめと今後の展望
今回、SRE が関わる領域において分類し、Reliability と Developer Productivity 領域において、「Lean と DevOps の科学」を参考にしながらパフォーマンス指標を提案し、計測を行なった。
MTTR に関しては自動的に計測するツーリングが必要だと考える。今回はデータソースとして Postmortem を用いたが、Postmortem を書く基準が定まっていなかったり、Incident によっては発生時間、検知時間、復旧時間が記載されていないものもあった。MTTR 自体が有効な指標かどうかはまだ判断が難しいが、計測することによって、Incident Response の型化が期待できる。
Developer Productivity 領域の指標は、いずれも monorepo の master branch のみを対象であった。そのため、原則 Weekly Release であり、それに対してどれだけ HOTFIX が行われたか、というものを示すに止まった。今後は microservice 群にも範囲を拡大し、より広い範囲でのデプロイ回数の計測を行いたい。変更失敗率に関しては、何らかのルールとプロセスの追加によって計測可能にするアプローチが必要だと考える。(例えば PR に label をつけるなど)
今後、このようにあらゆるものを計測して可視化するアプローチが、SRE だけに止まらず、様々な領域で有効になっていくと考えられる。そのため、計測して可視化する一般的なアーキテクチャやデザインパターンについても探求したい。*13
また、今回提案した領域は飽くまで筆者が所属する規模の組織での話であることから、組織やビジネスの規模に対して SRE Practice をどのような順番で適用すべきかの Trail map のようなものを定義できれば、今後新規に SRE を採用する企業にとって大きな貢献になるだろう。
謝辞
本発表で話した内容は以前複数の会社の SRE Member と会話したことが元になっている。その場に参加いただいた @katainaka0503 , @kazoooto , @taisho6339 に心から感謝する。
筆者が所属する Quipper Ltd. の SRE Team およびすべての関係者に心から感謝する。
*1:https://www.ahsan.io/2019-05-26-sre-implements-devops/#:~:text=Site%20Reliability%20Engineering%20(SRE)%20and,team%20building%20and%20running%20software.
*2:そのような理由で、各社の取り組みを共有するSRE Loungeというコミュニティも存在する
*3:https://book.impress.co.jp/books/1118101029
*4:プロダクト2つ、開発者数100名程度
*6:https://aws.amazon.com/architecture/well-architected/?wa-lens-whitepapers.sort-by=item.additionalFields.sortDate&wa-lens-whitepapers.sort-order=desc
*7:そのバランスを取るツールが Service Level Objectives である
*8:なお、応用として障害発生時の MTTR に Number of the affected user をかけることも指標になりうるが、今回は運用が複雑になるため採用を見送った。
*9:Incident Metrics in SREでも MTTR を指標として採用すべきではない "these statistics(MTTR or MTTM) are poorly suited for decision making or trend analysis in the context of production incidents." とされている
*10:Datadog, Mackerel 等
*11:https://en.wikipedia.org/wiki/Monorepo
*12:https://argoproj.github.io/argo-rollouts/
*13:筆者が Cloud Native Days Spring 2021 Online で発表した Metric-Driven Decision Making with Custom Prometheus Exporter はそのパターンの1つと言えるだろう
 にも e515060 【Alexa対応】")