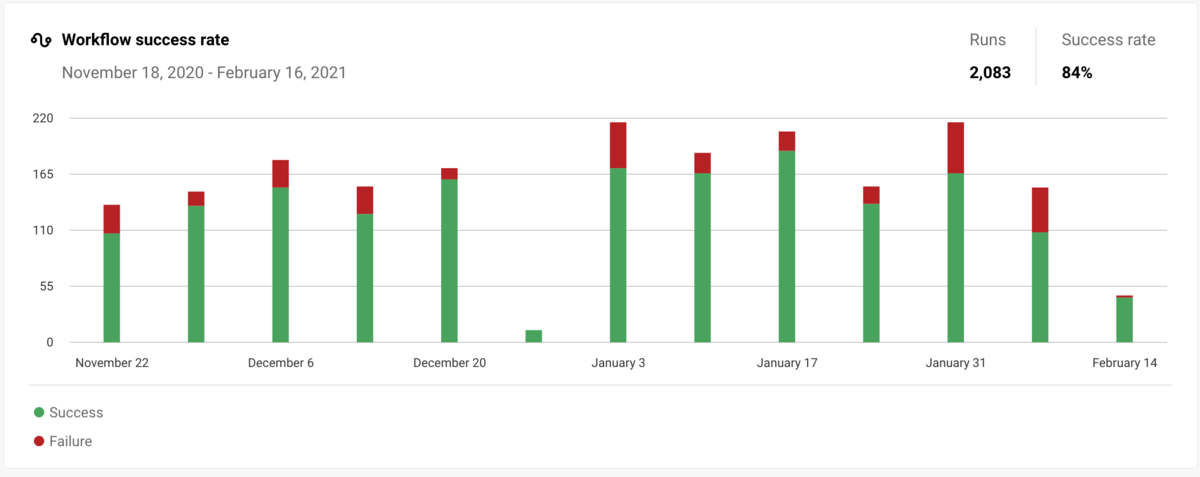
前回は Quick Start として Kubernetes の canary-example を動かしてみた。
今回は wait-approval の example を参考に Terraform で、gcs を backend に、cloud storage 上に object を作る。
- KeyPair 作成
- Piped のデプロイ
- Application の作成
- GCP Project と Service Account の作成
- Service Account の暗号化
- .pipe.yaml の内容
- Pipeline の実行
- まとめと感想
KeyPair 作成
Service Account といった secret key を安全に git 上に commit するには暗号化する必要がある。
PipeCD では WebUI 上で Encryption する方法が提供されている。
基本的にはこのドキュメントのまんまで、Key Pair を作成し、Piped を deploy する際に --set-file flag で Key Paid を格納、piped の configuration でそのファイル名を指定してやることで有効化される。
$ openssl genpkey -algorithm RSA -pkeyopt rsa_keygen_bits:2048 -out private-key ..+++ .............................................+++ $ openssl pkey -in private-key -pubout -out public-key
Piped のデプロイ
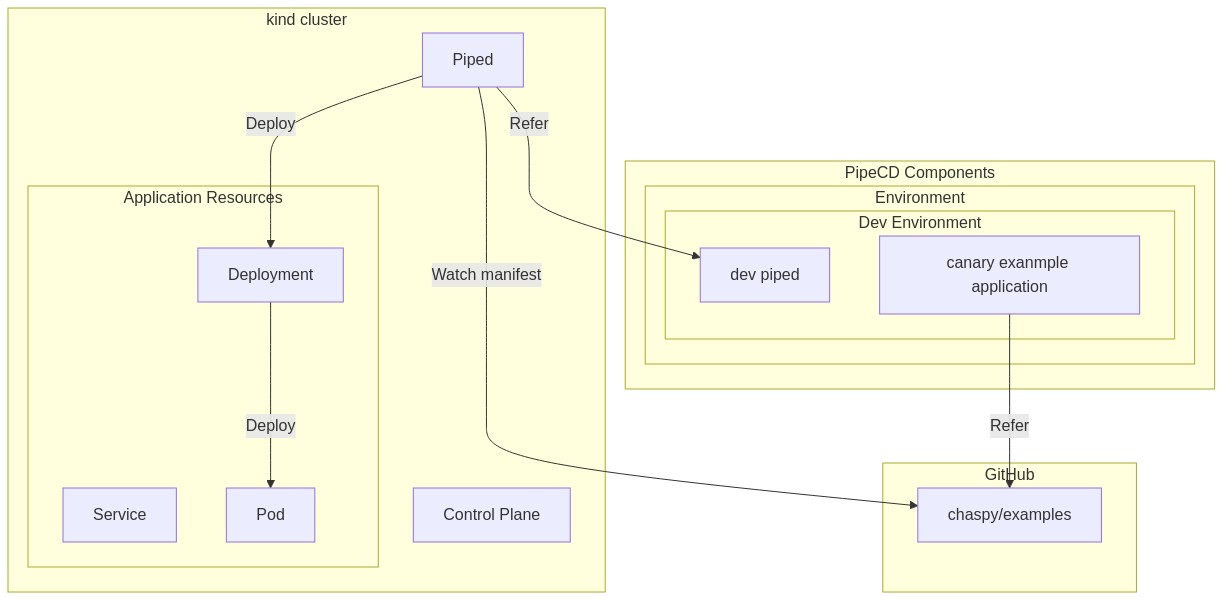
今回も Piped は local の kind 上で動かしている。Control Plane は別の検証環境を使っている。
このように helm で deploy している。前のステップで作成した KeyPair を格納している。
$ helm upgrade -i dev-piped pipecd/piped --version=v0.20.2 --namespace=pipecd --set-file config.data=piped.yaml --set-file secret.secretManagementKeyPair.publicKey.data=./public-key --set-file secret.secretManagementKeyPair.privateKey.data=private-key
piped の configuration piped.yaml は以下。
apiVersion: pipecd.dev/v1beta1
kind: Piped
spec:
projectID: pipecd
pipedID: 111111111-2222-3333-4444-5555555555
pipedKeyData: secret=
apiAddress: apiaddress:443
webAddress: https://webendpoint
syncInterval: 1m
git:
sshKeyData: secret==
repositories:
- repoId: chaspy-test
remote: git@github.com:pipe-cd/chaspy-dev.git
branch: main
chartRepositories:
- name: pipecd
address: https://charts.pipecd.dev
cloudProviders:
- name: kubernetes-default
type: KUBERNETES
- name: terraform-dev
type: TERRAFORM
config:
vars:
- "project=pipecd-dev"
- name: cloudrun-dev
type: CLOUDRUN
config:
project: pipecd-dev
region: asia-northeast1
- name: lambda-dev
type: LAMBDA
config:
region: ap-northeast-1
profile: default
- name: ecs-dev
type: ECS
config:
region: ap-northeast-1
profile: default
secretManagement:
type: KEY_PAIR
config:
privateKeyFile: /etc/piped-secret/secret-management-private-key
publicKeyFile: /etc/piped-secret/secret-management-public-key
(pipedKeyData と sshKeyData は set file で渡すのが良い。このように base64 にして直接記入しても良い)
cloudProvider の Terraform は少なくとも有効にしておくこと。
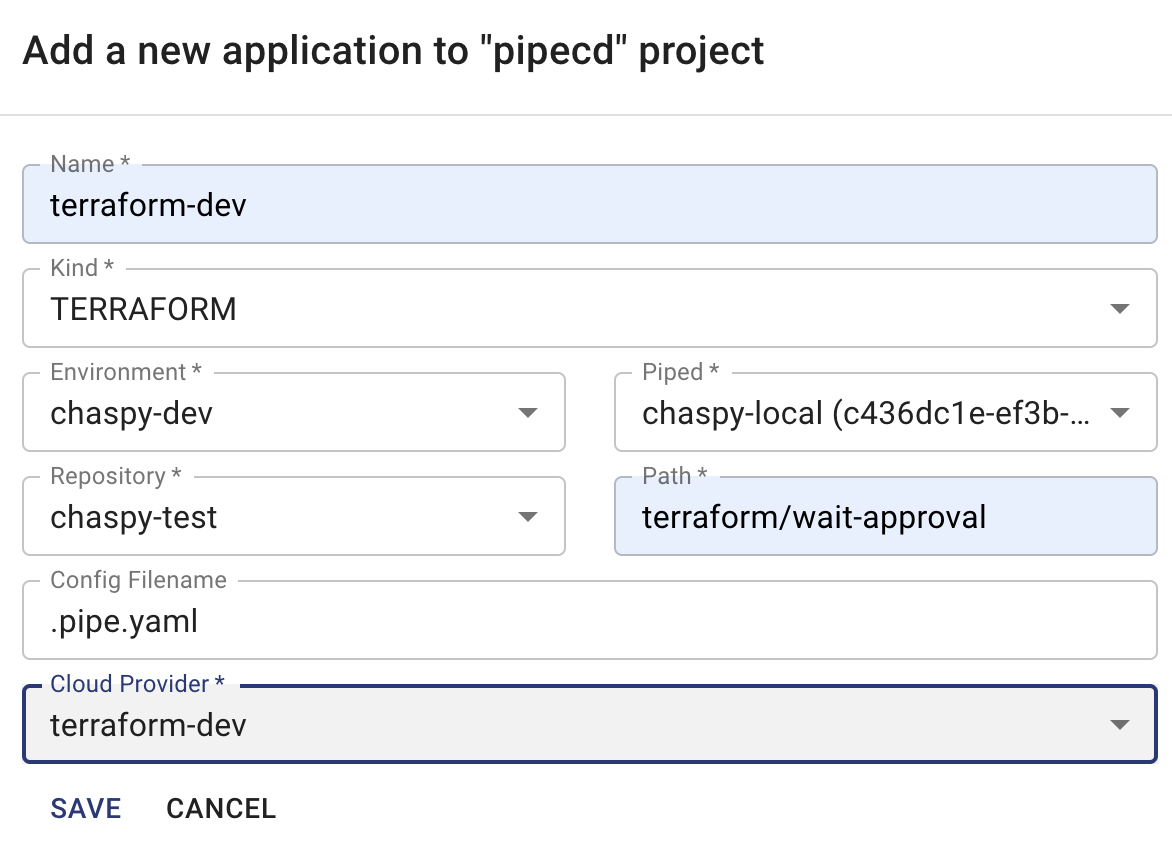
Application の作成
Web UI で Application を作成する。
こんな感じで作成すれば良い。
GCP Project と Service Account の作成
pipecd-dev という Project を作り、service account を作成します。Role にはいったんプロジェクトオーナーをつけました。(本当に運用するなら最小権限にしましょう)
Service Account Key を作成したら、json ファイルをダウンロードしましょう。
Service Account の暗号化
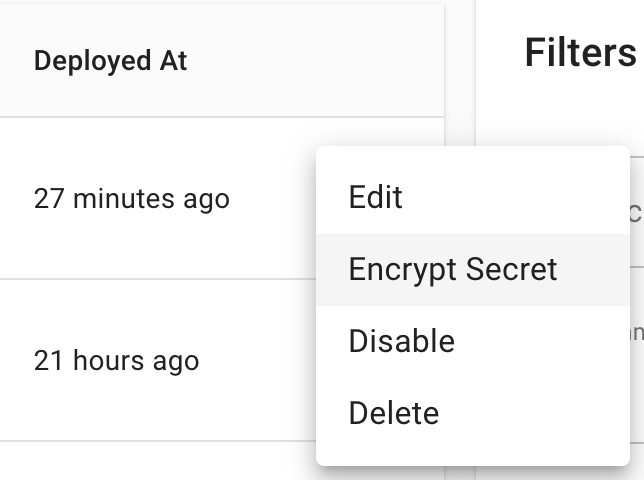
Service Account key の json file を WebUI の Application の右側から暗号化しましょう。
Application の右の3点リーダーから Encrypt Secret を選択
Service Account を貼り付けて Encrypt

Encrypted secret が表示されます。
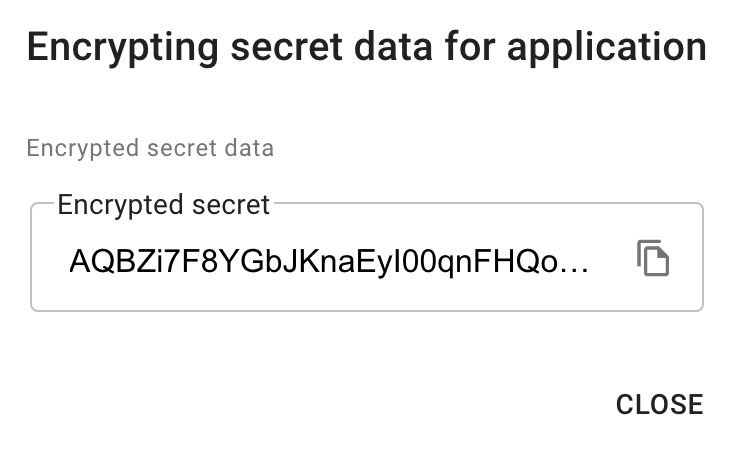
Encrypted Secret を .pipe.yaml に commit
https://github.com/pipe-cd/chaspy-dev/blob/main/terraform/wait-approval/.pipe.yaml#L14
このように encrypted secret の value に貼って push しましょう。
.pipe.yaml の内容
apiVersion: pipecd.dev/v1beta1 kind: TerraformApp spec: input: terraformVersion: 0.12.26 pipeline: stages: - name: TERRAFORM_PLAN - name: WAIT_APPROVAL - name: TERRAFORM_APPLY encryption: encryptedSecrets: serviceAccount: (encrypted secret)== decryptionTargets: - .credentials/service-account.json
この yaml は読んでそのままで、terraformVersion, stages, 暗号化された servicceAccount が記載されています。TerraformApp の Configuration のドキュメントは以下です。
Pipeline (stage) に設定可能な値は以下に記載されています。
今回は読んでそのまま、Plan を実行し、approval を待って、人間が approve したら apply する、という pipeline が組まれています。
Pipeline の実行
それではいよいよ実行していきましょう。
正しく設定が行われていれば、Application は Deploying の status になります。

Deployments タブから移動すると、Approval を待っている状態であることがわかります。

Plan 結果が画面下部に記載されています。
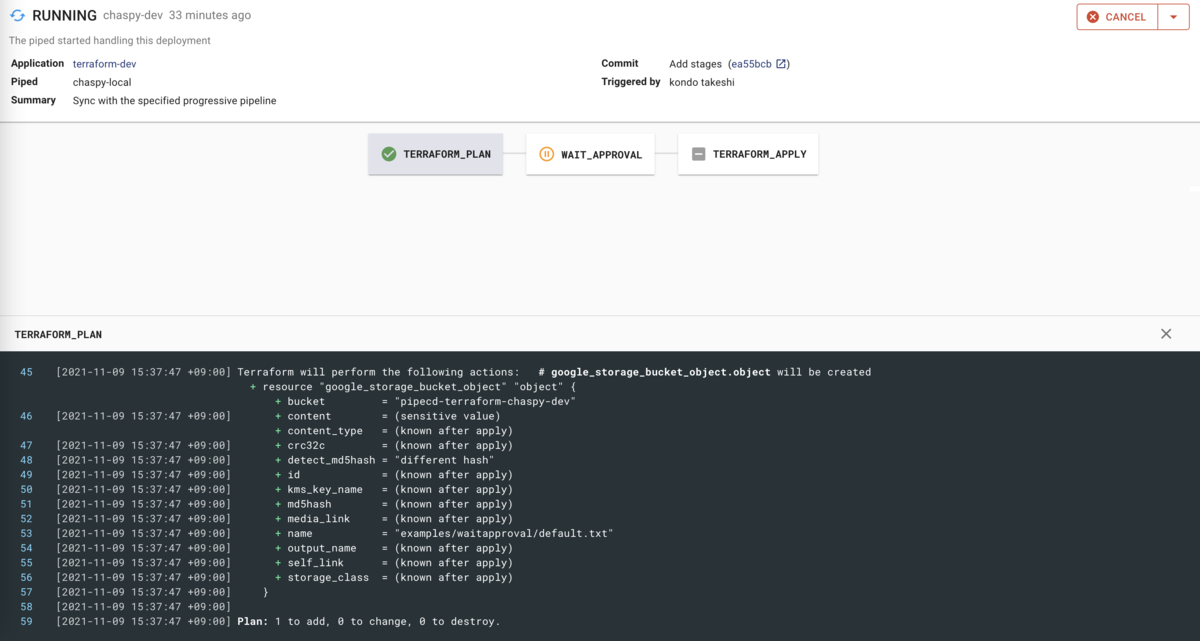
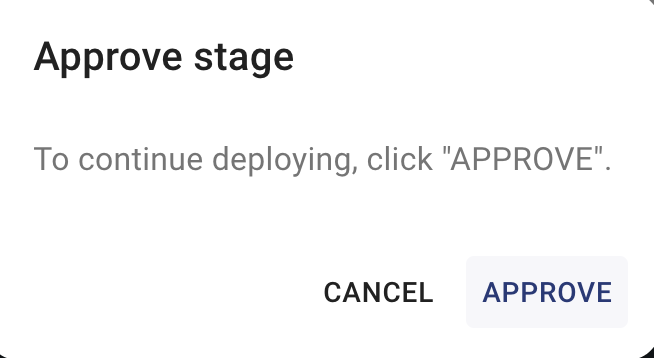
Wait Approval をクリックすると Approve ができます。
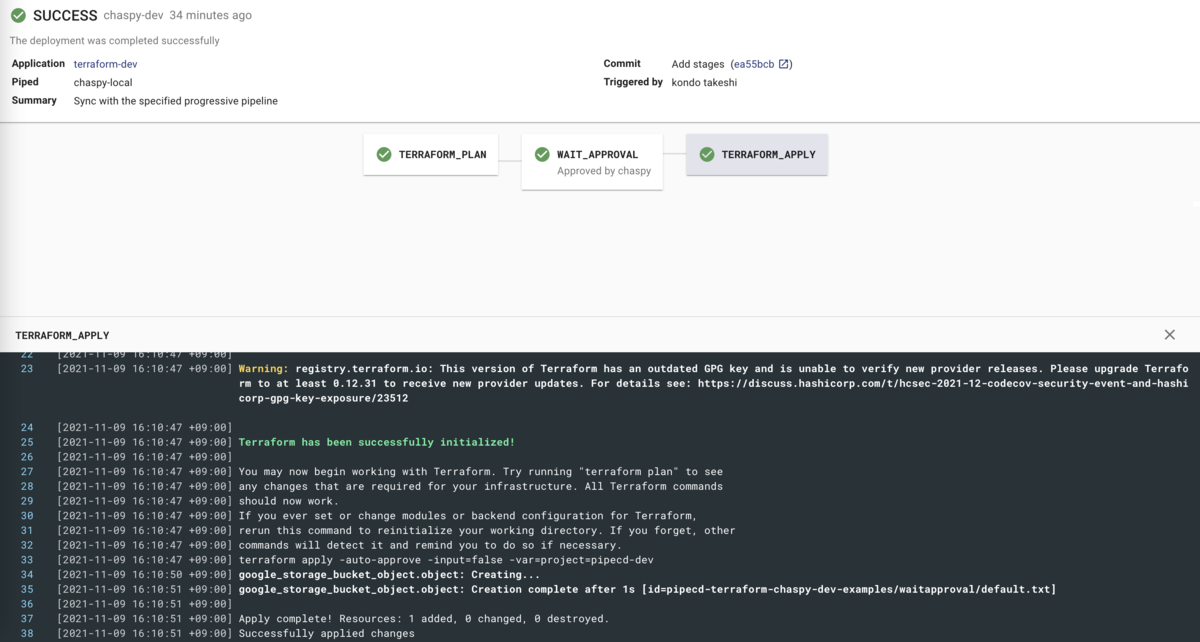
Apply 成功しました。
まとめと感想
PipeCD を使って Terraform の Plan と Approval, Apply を一通り実行してみました。
Terraform の場合、state に対して適用するかどうかの 0/1 になるので、ANALYSIS のような metrics 結果との組み合わせも、Canary Deployment みたいなことの実施も PipeCD レイヤーで持つのは難しいように感じます。何かしらの healthcheck endpoint なり metric が外部にあり、それが ready であれば apply, そうでない限り apply する、みたいなことは可能かもしれません。
競合になるのは Terraform Cloud あるいは自前の CI/CD と GitHub PullRequest による Deploy flow だと思います。Terraform に限って言えば(お金はかかるものの)Terraform Cloud がユーザの権限管理含めてリッチでしょうし。Plan による CI を実施して PR での Approve を実現できる点では GitHub Flow も遜色ありません。tfnotify https://github.com/mercari/tfnotify や tfcmt https://github.com/suzuki-shunsuke/tfcmt を組み合わせれば GitHub や (tfnotify の場合)slack への通知も可能です。
また、PipeCD は CD しかサポートしない点も GitHub Flow に比べてのデメリットになるかもしれません。tfsec や tflint など、CI での検査を組み込む場合は、自前で設定する必要があるものの、GitHub Flow にメリットがありそうです。
一方、すでに PipeCD Control Plane がある環境で、かつ Plan と Apply が実行できればいい、という状況であれば PipeCD は非常に楽で強力な選択肢になると思います。複雑になりがちなデプロイ設定も yaml で stage を書くだけですし、通知設定も yaml を書くのみです。どのみち必要になる Terraform の state backend の設定を終えて Application の箱と piped をデプロイすれば安全なデプロイパイプラインを簡単に組むことができます。
PipeCD という、複数の Cloud Propvider をサポートする共通のデプロイコンポーネントを採用するメリットは、今後他の Provider を同時に使った場合のシナジーであったり、マルチテナントを採用し、各開発チームごとに任意の Deploy Pipeline を自律的に設定可能な点があると思います。(これは Terraform provider に限りませんが)Many repo で細かく Terraform repository / state を切る場合は、この準備の楽さはメリットになるかもしれません。
引き続き他の Provider のデプロイを試していきます。














 にも e515060 【Alexa対応】")