pipecd.dev
これを動かす。
PipeCD とは
汎用的なデプロイツール。Kubernetes だけでなく、Cloud Run, Lambda, Terraform, ECS をサポートしている。
Control Plane としての PipeCD と、エージェント的に動く Piped の2つのコンポーネントからなる。
WebUI を提供しているのは Control Plane。
エージェントである Piped が実際のデプロイを行う。
デプロイパイプラインは Git Repository に保存し、Piped がそれを参照し、その指示通りにデプロイを行う。
用語や概念は Concepts ページに掲載されている。
pipecd.dev
Architecture
今回は Control Plane, piped ともに local の kind cluster に行う。
適宜公式ドキュメントを参照しながら自分の理解を整理していく。
Prerequisite
筆者の動作環境は macOS Big Sur version 11.3.1
helm
helm.sh
v3.7.1
$ helm version
version.BuildInfo{Version:"v3.7.1", GitCommit:"1d11fcb5d3f3bf00dbe6fe31b8412839a96b3dc4", GitTreeState:"clean", GoVersion:"go1.17.2"}
kubectl
kubernetes.io
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.3", GitCommit:"ca643a4d1f7bfe34773c74f79527be4afd95bf39", GitTreeState:"clean", BuildDate:"2021-07-15T21:04:39Z", GoVersion:"go1.16.6", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.1", GitCommit:"5e58841cce77d4bc13713ad2b91fa0d961e69192", GitTreeState:"clean", BuildDate:"2021-05-21T23:01:33Z", GoVersion:"go1.16.4", Compiler:"gc", Platform:"linux/amd64"}
kind
kind.sigs.k8s.io
$ kind version
kind v0.11.1 go1.16.4 darwin/amd64
クラスタを作成しておく。
$ kind create cluster --name pipecd-quickstart
Creating cluster "pipecd-quickstart" ...
✓ Ensuring node image (kindest/node:v1.21.1) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-pipecd-quickstart"
You can now use your cluster with:
kubectl cluster-info --context kind-pipecd-quickstart
Not sure what to do next? 😅 Check out https://kind.sigs.k8s.io/docs/user/quick-start/
Install
1. Cloning pipe-cd/manifests repository
pipe-cd/manifests を clone しておく。
2. Installing control plane
Control Plane を install.
helm -n pipecd install pipecd ./manifests/pipecd --dependency-update --create-namespace \
--values ./quickstart/control-plane-values.yaml
NAME: pipecd
LAST DEPLOYED: Sat Oct 30 20:10:09 2021
NAMESPACE: pipecd
STATUS: deployed
REVISION: 1
TEST SUITE: None
pod が deploy される。
$ kb get po -n pipecd
NAME READY STATUS RESTARTS AGE
pipecd-cache-6fbf867d56-ln6wn 1/1 Running 1 16h
pipecd-gateway-5ccd5cb8f8-z2fpp 1/1 Running 27 16h
pipecd-minio-6ffb69ff5-zvbv9 1/1 Running 1 16h
pipecd-mysql-55bc4f9495-rlphc 1/1 Running 1 16h
pipecd-ops-59d6b9bc9d-kv4bn 1/1 Running 12 16h
pipecd-server-77fcbc96f4-gjdmm 1/1 Running 11 16h
3. Accessing the PipeCD web
PipeCD の Web UI にアクセスする。
$ kubectl -n pipecd port-forward svc/pipecd 8080
http://localhost:8080 にアクセスし、quikcstart project に hello-pipecd の user name / password でログインする。
なおこの値は以下でプリセットされている。
github.com
4. Adding an environment
次に Environment。これは単なる Logical Group で、以降 Piped を設定するために必要なので作る。
5. Installing a piped
次にエージェントである Piped をインストールしていく。まずは Control Plane 側で piped の id と key を発行する。
id と key は控えておく。
.env につっこむ。
export PIPED_ID="3a23d2d6-e0ce-4659-98ea-721e07055cc3"
export PIPED_KEY="1m62gdfvmw2tvbujroqcnav6m8h6f2aqnj9m2t3ajarm1288vg"
これで Control Plane 側に箱ができたので、この id と key を使って local cluster に Piped をデプロイしていく。
piped-values.yaml はこんな感じになる。
args:
insecure: true
config:
data: |
apiVersion: pipecd.dev/v1beta1
kind: Piped
spec:
projectID: quickstart
pipedID: 3a23d2d6-e0ce-4659-98ea-721e07055cc3
pipedKeyFile: /etc/piped-secret/piped-key
apiAddress: pipecd:8080
webAddress: http://pipecd:8080
syncInterval: 1m
repositories:
- repoId: examples
remote: https://github.com/chaspy/examples.git
branch: master
repositories には Deploy Pipeline が配置されている git repository を指定する。
pipe-cd/examples を fork しておく。
github.com
piped を helm でデプロイする。
$ helm -n pipecd install piped ./manifests/piped \
--values ./quickstart/piped-values.yaml \
--set secret.pipedKey.data=$PIPED_KEY
NAME: piped
LAST DEPLOYED: Sun Oct 31 12:23:24 2021
NAMESPACE: pipecd
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Now, the installed piped is connecting to .
piped がデプロイされました。
$ kb get po
NAME READY STATUS RESTARTS AGE
pipecd-cache-6fbf867d56-ln6wn 1/1 Running 1 16h
pipecd-gateway-5ccd5cb8f8-z2fpp 1/1 Running 27 16h
pipecd-minio-6ffb69ff5-zvbv9 1/1 Running 1 16h
pipecd-mysql-55bc4f9495-rlphc 1/1 Running 1 16h
pipecd-ops-59d6b9bc9d-kv4bn 1/1 Running 12 16h
pipecd-server-77fcbc96f4-gjdmm 1/1 Running 11 16h
piped-58575956f7-jqxwr 1/1 Running 1 73s
6. Configuring a kubernetes application
次に Application を設定していきます。Application とはデプロイ対象のことです。例えば Kubernetes であればデプロイ対象の manifest - Deployment や Service に加えて、それをどのようにデプロイするかの Strategy や Notification などが記述できる KubernetesApp という Custom Resource を .pipe.yaml という名前で git repository に配置します。
公式の Example 通り、canary example を使います。
github.com

しばらく待つと Sync されます。

初回は Application の状態が表示されません。

こちらももうしばらく待つとちゃんと表示されます。

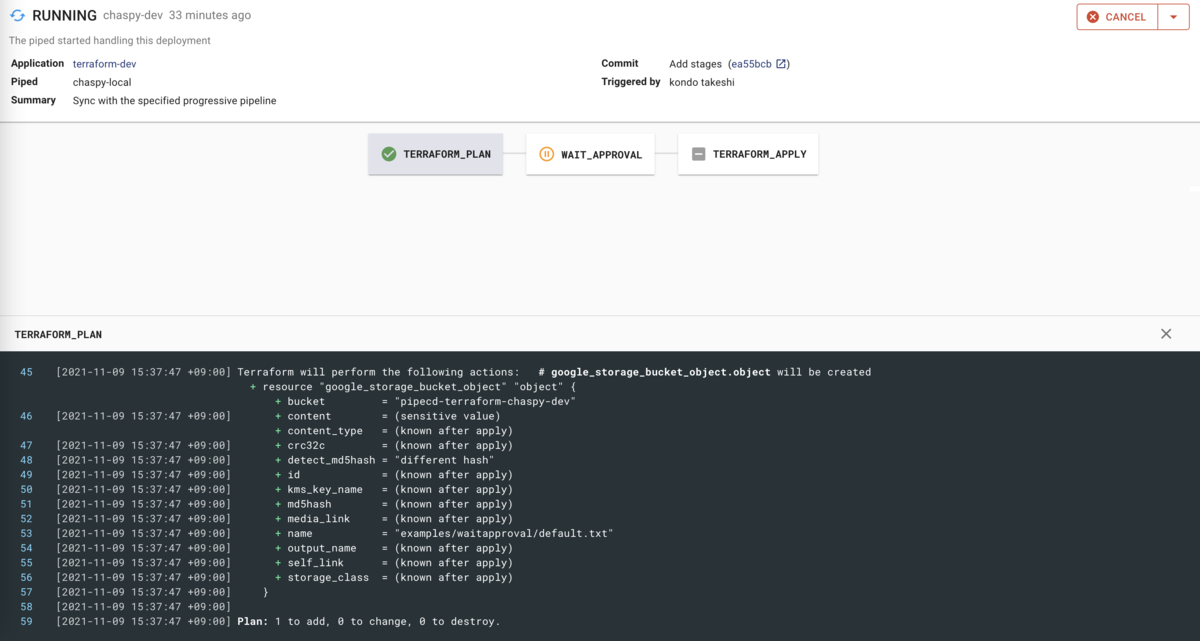
7. Let’s deploy!
それでは Deployment の対象の Image のバージョンを変更してみます。
v0.7.0 から v0.8.0 に変更します。こういう PR になります。
github.com
PR をマージしたあと、Web UI を眺めていると...
新しい Deployment が作られました。

一瞬 OutOfSync の Status になりますが、すぐに戻りました。

Deploy 完了です。

改めて今回の KubernetesApp の定義を見てみます。
github.com
apiVersion: pipecd.dev/v1beta1
kind: KubernetesApp
spec:
pipeline:
stages:
- name: K8S_CANARY_ROLLOUT
with:
replicas: 10%
- name: WAIT
with:
duration: 10s
- name: K8S_PRIMARY_ROLLOUT
- name: K8S_CANARY_CLEAN
KubernetesApp の Configuration の説明は以下のページにあります。
pipecd.dev
pipecd.dev
この定義によると、まず 10% の Replicas を新しいバージョンに切り替えて、10秒待ったあとに、Primary の Deployment =残りを切り替えて、最後に Canary 用の Deployment を削除します。
Primary や Canary という概念の説明、そして各ステージで実行できる操作については K8S-[PRIMARY|CANARY]_* は公式ドキュメントに記載されています。
まとめ
今回動かしたものをまとめるとこんな感じになる。
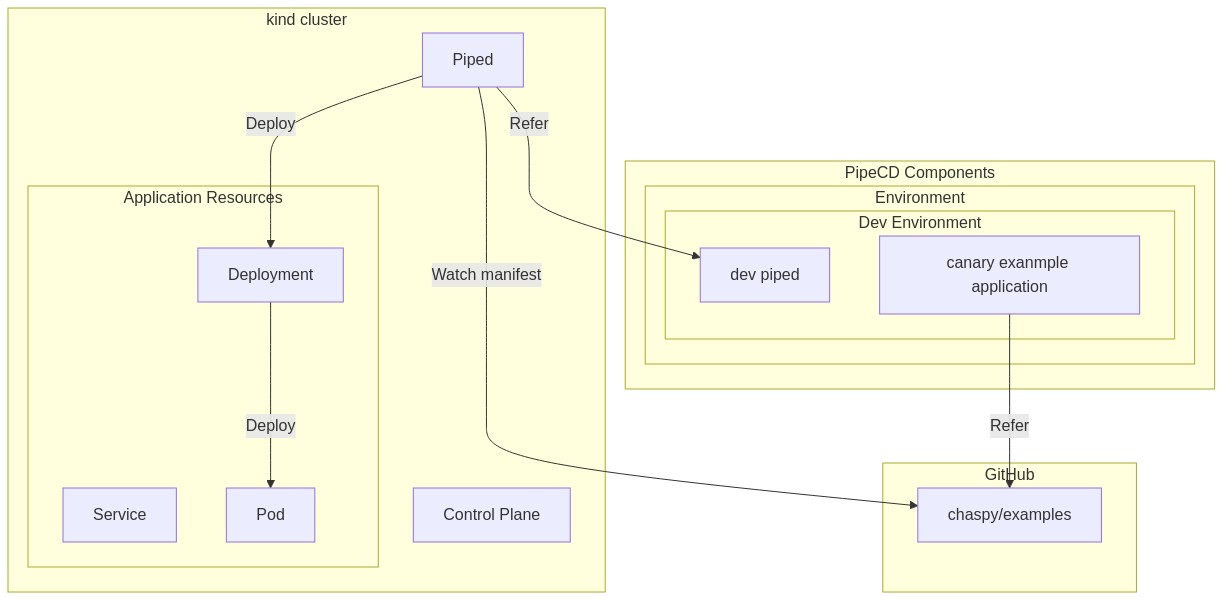
- PipeCD の Control Plane 上で用意した Components は Environment, Piped, Application の3つ。
- Environment は単なる Logical Group
- Piped は Control Plane 上で登録したあと、ID と Key を実際にエージェントとして動く Piped に認識させて通信させる
- Application は Git Repository 上にあるリソース定義とデプロイ設定が書かれたものを参照する。今回は KubernetesApp というものがデプロイ定義になる。
- エージェントとして動く Piped は Git Repository 上のデプロイ定義および manifests file の変更を Watch し、GitOps 的に対象リソース(Application)をDeploy する
- 今回の例だと Deployment の image version を変更した
- Canary 設定に則って新規バージョンを Deploy した
※実際に Control Plane として動いている Components の詳細は割愛した。また、それらが "PipeCD Components" を動かしている。
ArgoRollouts / ArgoCD との比較
今回の例、Kubernetes Deployment を Canary 的にデプロイするというケースにおいてのみいえば、両者に大きな差はない。
用語を見ても ArgoRollouts とできることは大差なさそうである。(Analythis の詳細や Integration には差があるかもしれない)
UI も ArgoCD と結構似ている。
argoproj.github.io
argo-cd.readthedocs.io
Argo Rollouts が Kubernetes Native な Resource として Replica Set を操作することに対して、PipeCD はあくまで Deployment を操作して Canary Deploy を実現している。
PipeCD の特徴
この quickstart をなぞっただけでわかることは少ないが、Multi Tenacy と Kubernetes 以外のリソースも GitOps による Deploy ができる点が大きな特徴のように見える。
Overview にあるところの Multi-provider & Multi-Tenancy だ。
pipecd.dev
社内の共通デプロイ基盤として作られた経緯もあり、おそらく社内で1つ、あるいは求められる信頼性やある程度の大きさの組織単位で Control Plane を構築、運用し、あとは各チームや運用主体の単位に Piped を Install して自律的にデプロイの設定を入れていく。
CI と CD の分離はもちろんのこと、CD を Piped というエージェントを入れて行うことで、デプロイの設定も各開発チームで自律的にできるような世界を目指しているように見える。
Kubernetes のデプロイだけでいえば ArgoCD & ArgoRollouts(Canary Release)、FluxCD があるし、Kubernetes や ECS などのよりメタなデプロイツールとしては Waypoint がある。今後も他のツールを使ったり、PipeCD の他の Cloud Provider に対するデプロイも試していきたい。











 にも e515060 【Alexa対応】")


