作った。
シリーズものです。Prometheus Exporter としては7作目。
経緯
CircleCI の Insight API に想いを馳せている。https://t.co/xYcVo8IO5F CI の時間を分析する場合、うちの場合は差分検知をやってる関係で、差分がない場合 CI が立ち上がるがすぐ halt するみたいなことをやってるせいで正しい統計情報が取得できないため、別 workflow を nightly で全部ぶんまわし、
— Takeshi Kondo (@chaspy_) February 7, 2021
その分析結果を Insight API で取得して、長期的な CI 時間のトレンドを取得できないかと考えている。nightly でやる理由は前述の差分検知の問題が1つ。あとは実際の CI 実行後に Job の CI 時間を Datadog 等に Push するアプローチは Sparse metrics となってしまう。
— Takeshi Kondo (@chaspy_) February 7, 2021
Sparse metrics はいわゆる Event 的にデータが蓄積されるため、分析に向かない。Line でつなげばそれらしきトレンドは見えるものの、push だと実行頻度も Job によってまちまちなので、十分なサンプル数を得られない。そこで Nightly で常時・定期実行し、それを分析した結果を Gauge として
— Takeshi Kondo (@chaspy_) February 7, 2021
貯めることで十分なデータ量が得られ、分析もしやすくなると考えている。Datadog に Histgram として送るのはどうかと考えたが、その統計情報の Time Window, Flash Interval は結構短かったはずで、(1分とか?ドキュメントに載ってないが)要件にマッチしない。https://t.co/DghjLAXxja
— Takeshi Kondo (@chaspy_) February 7, 2021
https://t.co/KBvS95gsS8 summary metrics for a project's workflows が workflow の分析によさそう。これ自体が metrics.duration_metrics として min, median, p95 など計算済み情報を提供してくれる。time window も指定できるので、Nightly を1時間に一回なら 24h、1日1回なら 7days、30days とか
— Takeshi Kondo (@chaspy_) February 7, 2021
こっちが job に対してなので、この2つの api を使えばなんとでもなりそう。https://t.co/ube4vXWsTM なお CircleCI GUI の Insight からもこういう統計情報は得られるが、特定の Time Window での統計値のみで、推移は追えない。
— Takeshi Kondo (@chaspy_) February 7, 2021
というわけで circleci-insight-prometheus-exporter のネタができた。いったん毎時走ってる nightly workflow が既にあるのでそれを対象に使ってみよう。
— Takeshi Kondo (@chaspy_) February 7, 2021
CircleCI Insight API を Prometheus 形式で Export するやつできた。Workflow / Job 両方出した。これで遅いジョブ、ボトルネックになってるジョブからあたりをつけて改善につなげられる土台ができた。https://t.co/LNb2EqSDnV
— Takeshi Kondo (@chaspy_) February 13, 2021
解決したい課題
所属している会社では monorepo を採用しており、大量の Build と Test と Deploy とその他いろいろの Job が超巨大ワークフローとして走る。
しかしまぁこれが遅い。改善を続けてきているがまだ遅い。そしてそれがどう遅い、何が遅いということが見えやすい状況とはいえない。
あと Flaky Test がぼちぼちあって、それによって脳死 Rerun が状態化している。よくない。
テストやビルドなんかは基本的にサービスを開発している Developer が詳しく、SRE が直接改善していくことはできないではないが、効果的とはいえない。
SRE としてはサービスの Observability と同じ構図で、Insights を得られる指標を提供し、その活用方法を組織にインストールして、それを Developer に活用してもらうということを CI でも取りたい。
CircleCI Insights では不足か
最初は多分うちの monorepo が裏のデータが大きすぎて GUI がうんともすんとも開かないみたいな状態で使い物にならなかったが、最近は十分活用できるレベルになっている。
API ではここで表示している値を取ってきてるだけなので、単に取り回しの問題で、Datadog に送ったほうがよりカスタマイズ性があがるという理由である。
サマリを把握する分には CircleCI Insights の GUI で十分である。
これまでやってきたこと
これまでも Insights API が出る前から Job や Job 内の Step ごとにかかった時間を Push で Datadog に送るなどしていた。
しかし活用が難しい。なぜか。それは前述したように、Sparse metrics になるから。
Push として metric を送る場合、それは Event 的なデータとなる。継続的な"状態"を示すデータではない。これは解析しづらい。データ量が不足するということと、データ量自体が得られるかどうかの頻度が metric によるからである。適当な間隔で Aggregation / Rollup したりなんたりの処理が必要で面倒である。
そういうわけで値自体はとれていたが活用には至っていなかった。
差分検知に関する問題
これは今回の件と関係するようで関係しないんだが、弊社では Build / Test の時間を短縮するために独自の差分検知の仕組みを使っている。
これは monorepo 内の各サービス(ディレクトリがトップレベルで切られている)の sha1 を Kubernetes の configmap に保存しており(ここに置くのが良いのかというのはある)ここと差があれば差分ありと判定されビルドやテストが走る。差分なしと判定されればビルトやテストはスキップされる。
...んだが、CircleCI の Workflow は Dynamic に構成することはできない。条件によってこのジョブを走る、走らせない、みたいなことができない。そのため、ジョブ自体は走るがすぐに halt するということをしている。
これによって何が問題かというと、前述する metric がスキップしたものとそうでないものが区別できない点にある。これは Insights の情報も同じである。
その点で GitHub Actions の Path filter は優位にあり、CircleCI も現状開発中のようだ。
https://t.co/y8yrLxgt0a https://t.co/4bJUd2RUjf
— Fumiaki MATSUSHIMA (@mtsmfm) January 18, 2021
どうするのか
大きく2点の対応が必要。
- ビルドやテストなど、傾向を追いたいものは Nightly で定期的に実行し、統計情報を安定的に取得する
- よりコントローラブルにするために Insights API の結果を Prometheus 形式で Export して Datadog に送る
今回作った OSS は 2 を解決するものであり、1 は別途行う必要がある。
CircleCI Insights は結構イケていて、統計情報を提供してくれる点が大きい。これまで自前でやっていた"Duration Second" という事実を Event 的に送っても活用は難しい。CircleCI Insights に統計情報の計算はお任せして、その推移を追って活用することができる。
統計情報というのは API のページを見てもらえばわかるが一定の Time Window における Job / Workflow の Success Rate や Duration Second の P95, median, min, max などのことである。
結果
いい感じ。
- Workflow ごとの Success Rate
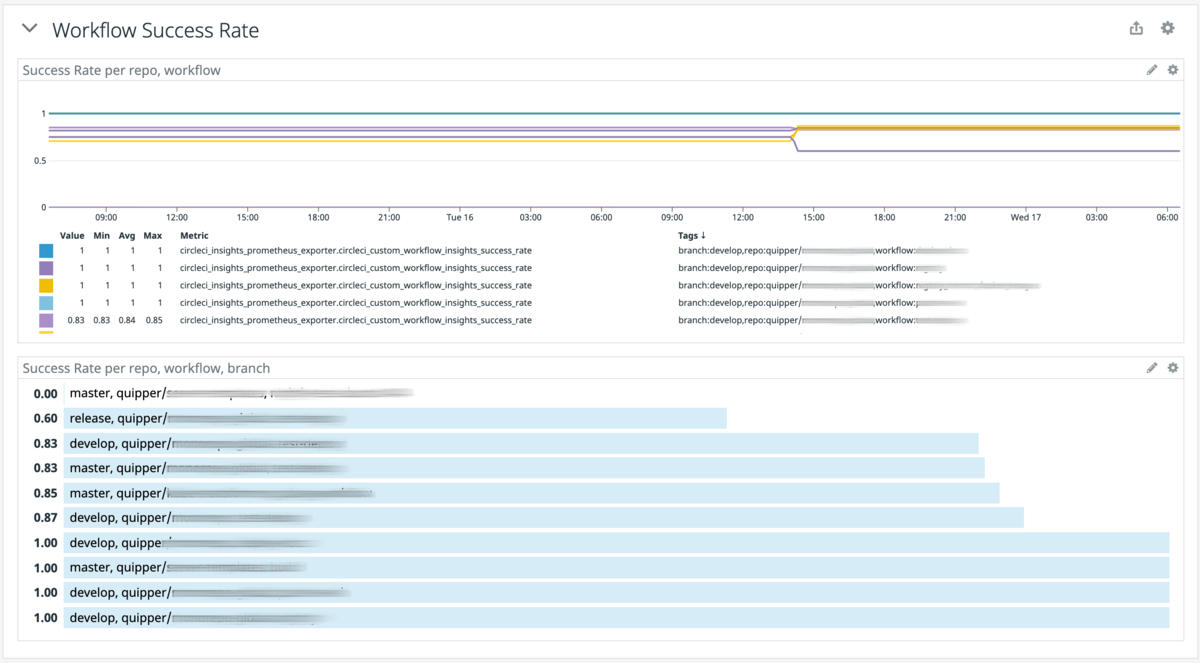
- Workflow ごとの Duration metrics, median
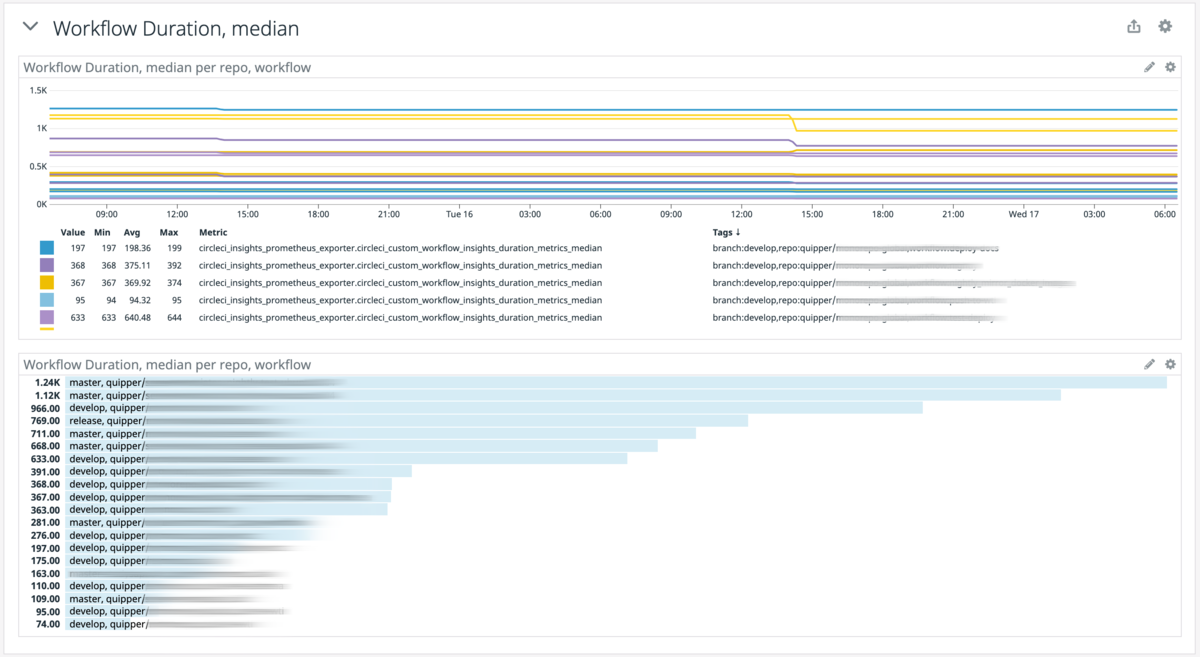
- Job ごとの Success Rate
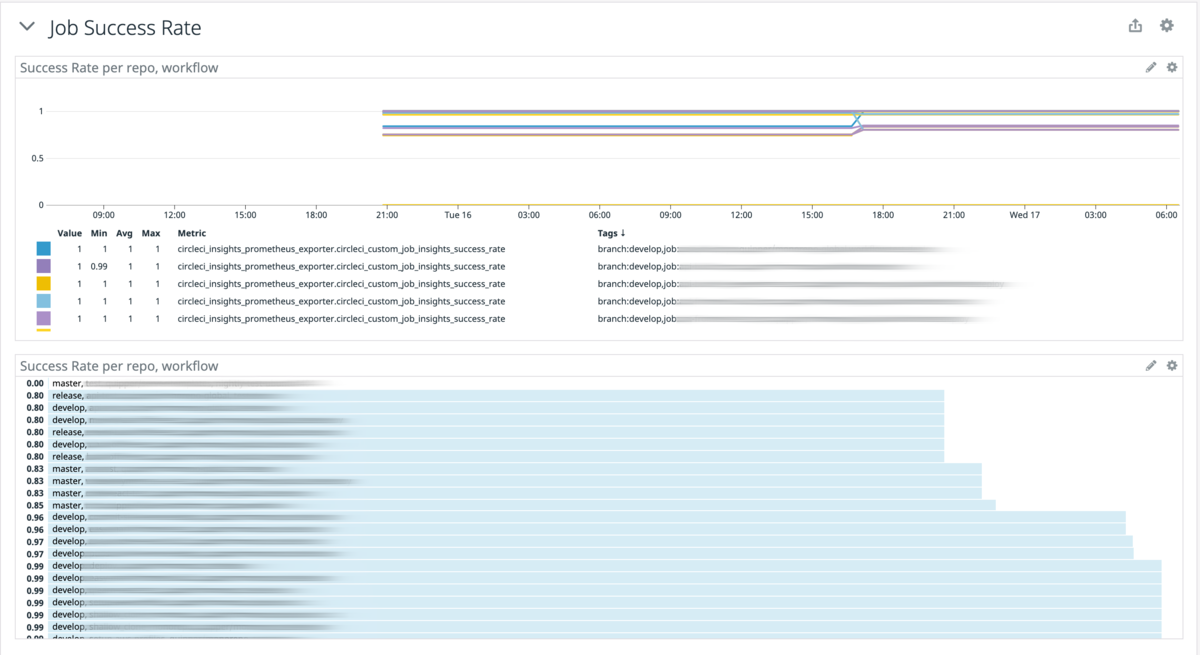
- Job ごとの Duration metrics, median
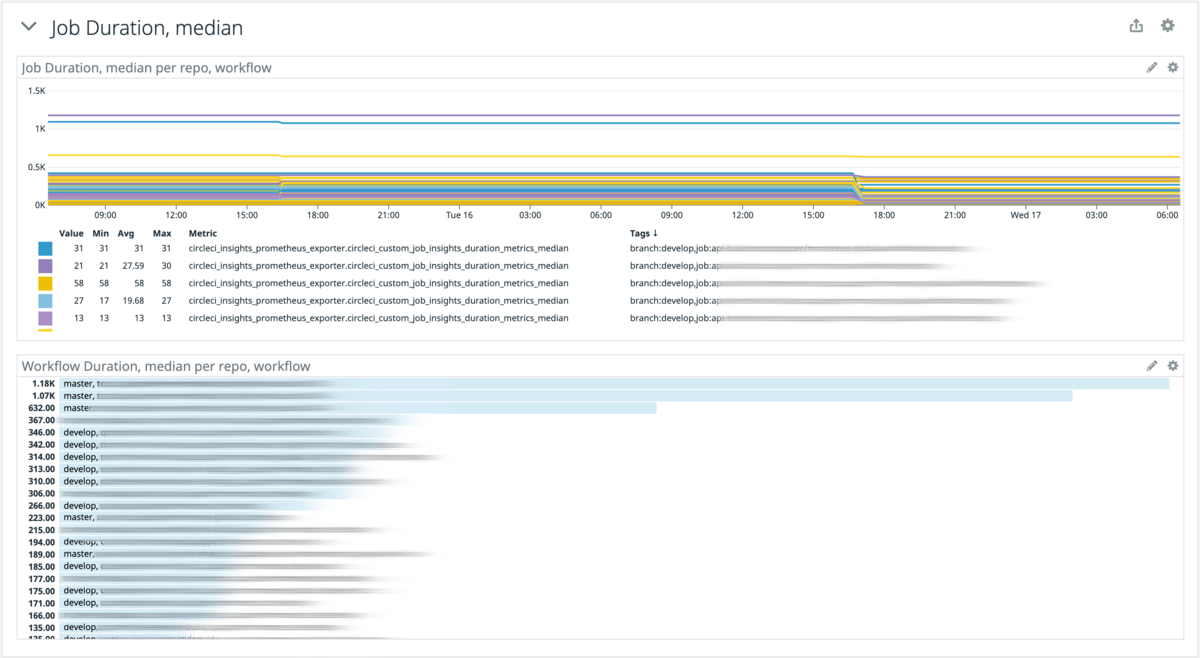
「やだ、、、私のテスト/ビルド、遅すぎ?」みたいなことがすぐわかって便利ですね。
まだこれらは差分検知の影響もあって確からしい値じゃないものもあるのですが、それでもそれなりに事実に近い結果は出ていそうです。
わかっていない点
CircleCI API の Rate Limit
CircleCI の api の rate limit っていくらなの。
— Takeshi Kondo (@chaspy_) February 13, 2021
rate exceeded のエラーをよくもらう。(後述するが API call 数が多いので)
これ結局いくつが上限なのかわかってない。
実際に動かすときは30分に1度実行するようにしていて、それだと大丈夫そう。
CircleCI Insights の計測間隔
metric を見る限り、last-7-days の time window にすると、24時間は同じ値を返し続けているように見える。その瞬間から24時間前を常に出しているわけではなく、1日に1度バッチ的にリフレッシュしているようだ。
last-90-days にした場合、GUI 上はグラフが週に一度しか変わってないように見えるので、もしかして API でも 7 days に一度しかこの値はリフレッシュされないのか?という点を気にしている。
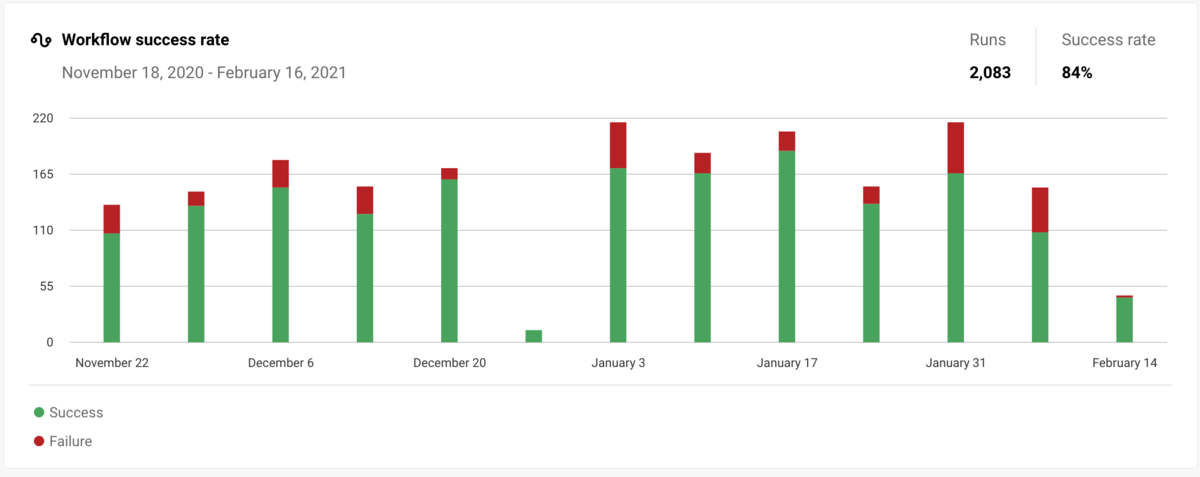
毎回瞬間ごとに計算する必要はないと思うが、せめて 24時間に一度は Time window が伸びても計算しなおしてほしい。表示が重くなるから GUI 上だけそうなっているのかどうかはわかっていない。
改善したい点
OSS のほうの話です。
Repository / Branch の持たせ方
現状はそれぞれ環境変数で持たせていて怒りのループぶんまわしを決めているので無駄がすごく多い。
例えば repo が "chaspy/hoge,chaspy/huga" で、branch が"develop,release,master" だとして、chaspy/hoge はこの3つの branch が存在するとして、chaspy/huga に release branch がなかったとしても API call してしまう。
この辺は yaml みたいな構造データで設定をいれるべきなんだろうなあと思っている。
repo: - name: chaspy/hoge - branch - develop - master - name: chaspy/huga - branch - develop - release - master
Go の CircleCI SDK がない
これがあるがメンテされておらず、Ingiths API はもちろんサポートされてない。v1 まで。
v2 用のライブラリ書いてもいいかなーと思ったけどいったんパスした。このリポジトリ内でまず外部利用可能な感じにできたらしようと思う。
いまはなんかパッケの名前がそれっぽいがこれそうじゃなくて API call をラップした一連の処理群で切っている。
学んだこと
JSON-to-Go 便利
API Response 格納する構造体定義するのばりめんどいやんと思ったけどレスポンスペーストするだけでできてめっちゃ便利。
JSON-to-Go めちゃ便利やん https://t.co/6extUHBmY0
— Takeshi Kondo (@chaspy_) February 12, 2021
json.Unmarshal 便利
response を構造体につっこむの楽で便利。
最低限動いた。あとは残りを実装するだけ。JSON を Go の構造体にパースするの、json.Unmarshal で楽だった。
— Takeshi Kondo (@chaspy_) February 12, 2021
err = json.Unmarshal(body, &wfJobsInsight)
if err != nil {
return []WorkflowJobsInsightWithRepo{}, fmt.Errorf("failed to parse response body. body %v, err %w", string(body), err)
}
wfJobsInsight がその構造体。body は response body。
おわりに
AWS は go-sdk を使うだけって感じだったけど http response をそのまま扱ったので勉強になった。
うまく改善につなげられますように。
おまけ
いろいろ書いてデータ眺めて観察してわかった知見をまとめて話そうと思うよ。
なんでこいつ最近似たようなんばっかり書いてるの?と思った方は #CNDO2021 にきてくださいね。| Metric-Driven Decision Making with Custom Prometheus Exporter | CloudNative Days Spring 2021 ONLINE https://t.co/ILUFJhYU9M #CNDO2021
— Takeshi Kondo (@chaspy_) February 14, 2021